
今回は文字の抽出についてです。
あるセルから、特定の文字列を抜き出したいときは、どのような方法があるでしょうか。
例えば下の表を見てください。
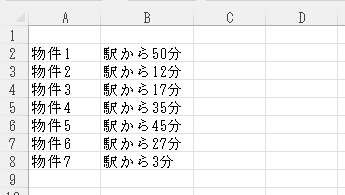
この表のB列から、分数だけをD列に入力したい。データ量が多いので、手動でやるには手間がかかる。
そんなときはMID関数を使ってみましょう。
MID関数は、「=MID(対象,開始位置,文字数)」を当てはめます。
対象はセルB2、開始位置は(左から)4(文字目)、文字数は2
ということで、「=MID(B2,4,2)」をD2に入力してみましょう。
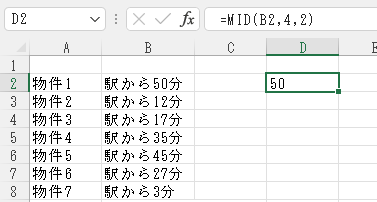
うまくいきましたね。では、D3以降のセルにもオートフィルで連続入力してみます。
※オートフィルとは、連続データの先頭のセルを選択したとき、右下にカーソルを合わせると十字が現れますので、それをドラッグしたまま下に引っ張ることで簡単に連続データ入力を行うことができる機能です。
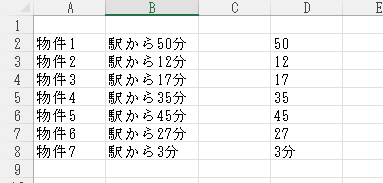
うまくB列の分数だけが抜き出せましたね。
ん?
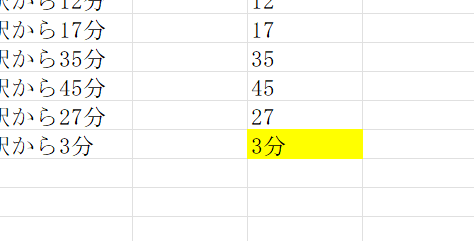
最後だけ「分」まで抽出されていまいました。これでは困ります。
物件6までは数字が2桁ですが、物件7だけが1桁の数字になっているため、MID関数で指定した、左から4文字目から文字数「2」文字目までを抽出する、という命令に従い「3分」となってしまったのです。
さて、ではどうすれば良いのか。
簡単に言えば、物件7だけ「=MID(B8,4,1)」というように、文字数「2」を「1」に変更すればいいだけです。でも、データ量がもっと多ければ、手動でこつこつ変更していくのは手間ですよね。

上の表に物件8を追加してみました。「駅から」が「Aくんの家から」になっていますし、分数も3桁です。MID関数で指定した、開始位置も文字数もこのままでは使えません。
しかし、よく見ると「から」と「分」は全てのデータで共通しています。つまり、数字の直前の「ら」が何文字目か、数字の直後の「分」が何文字目かが分かれば、MID関数で正しく抽出ができるはずです。
そこで使えるのがFIND関数です。FIND関数は、指定した文字列を特定の文字列で検索し、その検索文字列が最初に現れる位置を、左端から数えた位置を返します。
FIND関数は、「=FIND(検索文字列,対象,開始位置)」という式で構成します。
上の表の場合、検索文字列は「ら」、対象はB2、開始位置は1です。
式に当てはめると「=FIND(”ら”,B2,1)」となります。
※対象が文字列の場合、「“”」(ダブルクオテーション)で囲みます。
※開始位置とは、文字列のどの文字から検索を開始するかを指定するもので、省略可能です。省略した場合は1となり、文字列の最初から検索をしてくれます。
これをE列に挿入します。
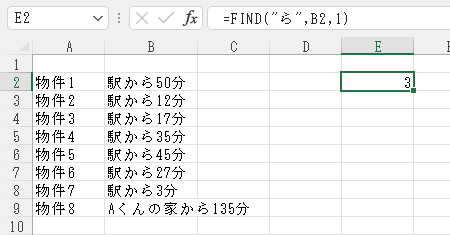
「ら」の位置である「3」が返されました。
ただ、MID関数では抽出する文字が左から何番目にあるかを指定しなければならないので、物件1の例では「5」が何番目になるかが分からなくてはなりません。
というわけで、式に+1をします。「=FIND(”分”,B2,1)+1」
これで「4」になりますので、これをMID関数に挿入して使えばいいというわけです。
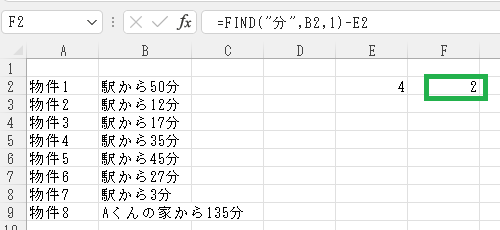
同じように「分」のほうもFIND関数で検索してみましょう。
「=FIND(”ら”,B2,1)」
こちらは、文字数を知りたいので、「分」の位置から、開始位置(E2)の数字を引きます。
あとは、FIND関数で求められた値をMID関数に挿入するだけです。
「=MID(B2,E2,F2)」
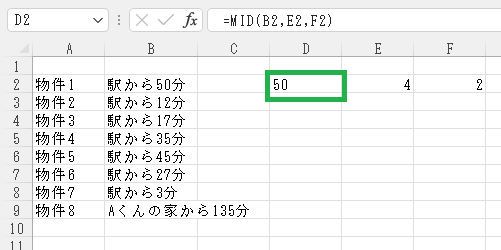
ばっちり「50」が返されましたね。冒頭と同様にオートフィルで連続データ入力を行います。
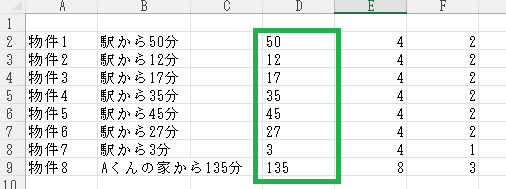
数字だけが抜き出されました!
FIND関数で求めたE列・F列は非表示にしてしまえば、見た目もすっきりします。
あるいは、MID関数の中に全部入れ込んでしまうこともできます。
例えば、B2からの抽出の場合は、
「=MID(B2,FIND(“ら”,B2,1)+1,FIND(“分”,B2,1)-(FIND(“ら”,B2,1)+1))」
となります。とてもややこしくなりますが、1つ1つ見てみると、上記で説明したことばかりです。
ぜひ、いろいろお試しください。

